





In all but one case I can think of, PICO-8 specifies screen rectangles as X1,Y1-X2,Y2 (inclusive).
The case where it doesn't is clip(x,y,w,h).
This has always bugged me. But worse, I noticed recently that the virtual hardware registers for the clip rect are actually set up like the other API calls: X1,Y1-X2,Y2 (inclusive), which means the API is actually translating between the paradigms.
Now I realize clip() can't suddenly change to work the other way, but...
What if we had a new command next to it called clp(x1,y1,x2,y2) that worked the same as everything else, worked like the virtual hardware, returned the same values you'd get by peeking the virtual hardware registers, etc., and simply marked clip() as deprecated, much like mapdraw() is deprecated?
It would hardly be the only abbreviated API call, e.g. sgn().
What do you think, @zep?
 2 comments
2 comments

Right now, tostr(n) converts to decimal, and tostr(n,anything_except_nil_or_false) converts to hex.
Could it use the optional second arg as a base if it's a number? e.g.
>?tostr(255) 255 >?tostr(255,false) 255 >?tostr(255,true) 0x00ff.0000 >?tostr(255,16) 0x00ff.0000 >?tostr(255,10) 255 >?tostr(255,2) 0b0000000011111111.0000000000000000 |
For the sake of simplicity, you could limit it to the bases the parser can read. I think that's just decimal, hex, and binary.
3 comments


"Are you there @zep? It's me again, Margaret Felice."
I was thinking about how the option to show additional screens could open up the ability to write on-target dev tools to complement the existing IDE, and yet we're not really seeing any of that (yet).
I don't think it's a big deal that these additional screens are officially unsupported and you have to alter the pico8.exe command line to use them at all, because only a dev needs dev tools, and devs know how to alter command lines. I don't think that's why.
I think the problem with dev tools and debug libraries comes in the form of the token limit.
Any and all dev tools are going to take up tokens, and once you go past 8192 tokens, your app can't even launch. So someone with a nearly-finished app that's utilizing most or all of the allowed tokens is going to be absolutely unable to use any form of dev tool, debugging library, or even just print() debugging.
So...
Would it be possible to add a command-line option to increase the limit from 8K to, let's say, 32K tokens?
53 comments








I just discovered there's "> ..." quote block feature.
Except there isn't...?
If I do this:
this is my introduction > this is my quote this is my response |
I get this in the preview:

But when I click [Publish] it comes out like this:

Also, if this feature is intended to work, it should be in the [Formatting Help] helpbox.
3 comments
Hey @zep,
There are a lot of people who come here and learn to code by modding existing carts, and personally I think iterating on someone else's project is a fantastic way to learn stuff (I do it too), so I'd never want to discourage it, but sometimes it floods the BBS too, especially when someone does a workshop or class where everyone does it.
Could we get a Mods category under Cartridges?
That also might let you curate that kind of cartridge a little better, since a lot of them are only slightly different from the original, or indeed might not even work properly, and don't really belong in Splore, even though it's useful for junior programmers to share their work with each other here on the BBS and bounce ideas back and forth and so on.
12 comments






Hey @zep,
I'm not sure if this is related to the last += parser bug. It doesn't seem to be, but if it is, it's possible you already fixed it in your dev version.
Having a tab as whitespace in this construct:
t={1}
t[1] +=1
-- (with visible whitespace)
t={1}
t[1]⟼+=1 |
Produces an "unexpected symbol near +" error.
I copied the "see what the pre-parser does" trick to clipboard:
printh([=[t[1] +=1]=], "@clip") |
And got this when I pasted it back into an editor
t[1 ] = + (1) -- (with visible whitespace) t[1·]⟼·=·⟼·+·(1)·· |
Note that it only seems to do this if the left value is a table deref. Mind you, other complex lvalue patterns might also trigger it.
Maybe your regex needs some "\s*" patterns where it currently only has " *"?
I'll assume this is enough for you to go on. :)
2 comments

Hey @zep,
I've been messing around with software synth via the PCM trick and I feel like there's sort of a fundamental problem that's detracting a lot from the quality of what comes out the back end, needlessly so, not to mention making it uncomfortable to the listener's ear.
As far as I can tell, you're feeding the 5512.5Hz signal into the audio version of a "nearest neighbor" sampler to upsample it to the host OS' audio hardware sample rate, which is typically gonna be either 44100Hz or 48000Hz. That means repeating the sample values as many times as necessary to fill the gaps. In this case it'd repeat the same value around 8 times. This of course produces stairsteps on the 44100Hz+ "curve".
The issue with that is that modern audio hardware has really good fidelity and it's going to reproduce those sharp stairsteps very faithfully, effectively overlaying a constant 5512.5Hz triangle wave on the original wave that pulsates its amplitude based on how big the deltas between samples are in the original wave.
9 comments


I've discovered that printing the "\b" character (8) moves the cursor back based on the width of the most recent glyph that was printed.
So, @zep, I can understand where your mind was going with this, because you wanted it to be possible to back up over something like a kana character or a PICO-8 emoji with a single backspace. That does make sense.
However, I think unless you're going to keep a long history of what was printed before that, and where the cursor was for each glyph, it's going to cause problems, because right now it's only guaranteed to work for backspacing over one character, not more.
For instance, if I print("abしd\b\bcd"), it doesn't put "cd" in the right place, as shown below, where I highlight the overprinting in the second print by changing the foreground color to orange:
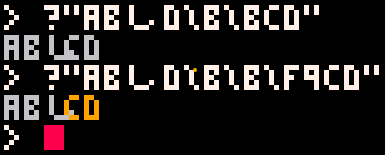
Point being, you're trying to be helpful to the user by remembering the width of the last glyph, but it's not helpful to the next user who wants to back up over two glyphs. It's not a game I think you can play to win. I think it'd be better just to set backspace.dx to a constant for the font, be it oem or custom.
0 comments
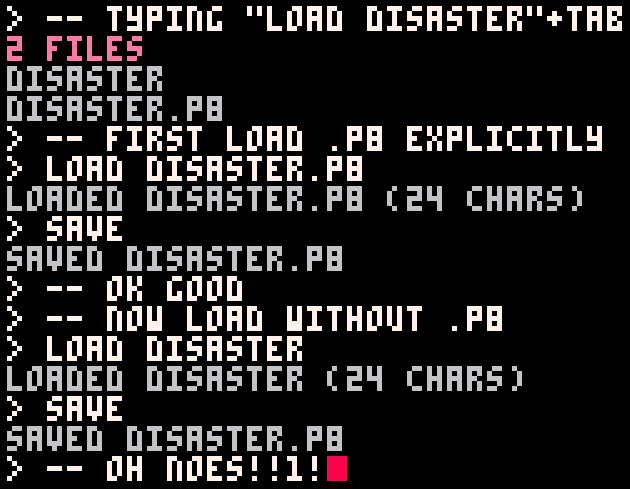
I noticed this while looking at load/save behavior for my QoL idea.
You can load a file that has no extension, because load will try the raw filename first without adding an extension.
However, when you save that file, it will automatically add ".p8" to the name, possibly overwriting an existing file while not overwriting the file you actually loaded.
Probably not going to happen much in practice, but potentially disastrous when it does happen.
 2 comments
2 comments
At the command prompt, if you try to load a filename with no extension:
load somefile |
It'll try these in order:
somefile somefile.p8 somefile.p8.png |
It'd be nice if #include worked the same way.
e.g. with vector.p8 in the same folder:
#include vector |
I think simply re-using the logic from load would work, because it behaves exactly the way I'm suggesting.
As for Lua files, it's probably best if the .lua extension has to be typed out explicitly, because you're essentially leaving the sphere of PICO-8 by using a raw lua file and it makes sense that PICO-8's name abbreviation would not apply. Plus this is the same behavior load already uses, so minimum effort required. ;)
1 comment
It'd be really intuitive and helpful if the select() function also detected a boolean value for the first argument, and returned the first arg if true and the second arg if not.
A lot of us write our own ternary function that does this anyway, because it can work around some gotchas with the cond and tval or fval structure, so this would obviate the need for it while extending the existing API in a very intuitive way.
e.g.
-- this works as you'd expect a C/C++/JS-style "cond? nil : that" ternary op to work this = select( cond, nil, that ) -- this doesn't, it returns 'that' regardless of 'cond' this = cond and nil or that |
Plus I think this would evaluate faster on the host.
Should probably also treat nil as false, btw, for maximal usefulness and congruence with Lua's concept of conditions.
2 comments

I can't see a way to disable the new "\#n" background-fill mode once it's been enabled. I've tried "0" for color 0, "G" for color 16, and "W" for color 32, but they just set the BG to black, and all other "0-Z" just repeat the palette. I've tried supplying a "-" for the color instead, I've tried repeating the "\#" code or just "#", I've tried various other symbols and the puny letters, and anything not in "0..Z" just sets it to black.
Is this a missing feature or is there supposed to be a way to do it? The manual says nothing of turning it off. Right now I have to start another print() to get back to no-BG mode and that seems... unintended?
I feel like it ought to be "\#-", based on the convention with the "\^" commands. Alternatively, "G" (or anything through "V") would technically make sense if you just consider bit #4 of the color to be a "transparency" bit.
2 comments

Before the most recent update, you could print anything below chr(32) and get an actual glyph in the output, aside from the obvious exceptions like \n and \t. For characters below chr(16) this is no longer possible, aside from chr(5), which I suspect is an oversight. In fact, that oversight is the "bug" that brought me here.
The thing is, this is a waste of 16 glyphs in the character set, and potentially up to 32 in the future if you add more control codes.
Can we get some kind of "raw" printing mode, where control character behaviors are completely ignored and their glyphs are simply printed?
Maybe turn the two oem/custom font selector characters into a single oem/custom toggle to free up chr(15), and use that as a raw-mode toggle, as in this pseudocode, where raw mode allows everything to be printed except the toggle itself, unless it is repeated:
fn print(s, ...)
raw = false
just_toggled_raw = false
for each char c in s
[ [size=16][color=#ffaabb] [ Continue Reading.. ] [/color][/size] ](/bbs/?pid=89089#p) |
5 comments
This is to do with the so-called "outpost" value, or the two's-complement wrap point, which in PICO-8's number system is 0x8000, or when printed as signed decimal, -32768.
Like the origin, 0x0000, it's technically not really signed, or maybe it's better to say it covers both signs simultaneously. Conventions assign the origin to the positive side, and the outpost to the negative side, but that's just a pragmatic choice for numbers that unavoidably behave strangely due to the encoding. The origin and the outpost are complementary values in this way.
(This is why 0 == -0 and -(-32768) == -32768 with a 16-bit signed integer, by the way.)
That being said, this is what I currently get for the outpost value:
> print(tostr(abs(-32768),true)) 0x0000.0001 |
Obviously, there's no "good" result when we can't represent +32768 with a signed 16-bit integer.
But this result is just plain wrong in every way, because it has no connection to anything someone might expect to get as an alternative to the impossible correct result. It's not equal to -(-32768), it's not close to +32768, and it's not even exactly 0.
2 comments
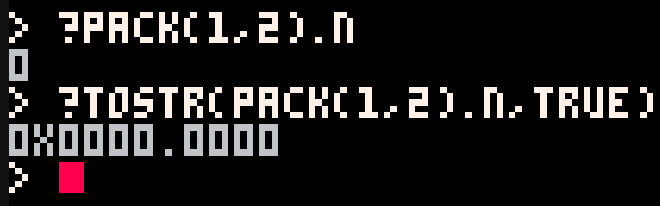
I'm surprised I haven't noticed this before.
I'm not sure if this is a regression in 0.2.1b or if it got outright broken, but @zep, I swear you fixed it in the past. But in 0.2.1b pack() is always setting the table.n value to 0:
 3 comments
3 comments
Hey @zep,
I know this is pretty minor, but I often find myself adding this to my programs so that I can use it in tables of functions/behaviors or other similar circumstances:
function nop() end |
It'd be cool, and kind of in keeping with the half-lua/half-asm feel of PICO-8 to have a handy built-in nop() function for such occasions:
function assign_behavior(o,b,f) o.behavior[b] = f or nop end -- saves me having to do this elsewhere: if(o.behavior[b]) o.behavior[b]() |
I can't be sure, but I bet it might be useful for some tweetcarts too.
Seems like it'd be trivial to add as an efficient built-in C-side function as well. No need to handle args or closures or anything, just spot it and return the empty set immediately.
Anyway, I know it's about as minor a request as a person could possibly make, but still, I figured I'd at least ask. ;)
PS: Honestly, I think even vanilla Lua could use this as an actual built-in, like a pseudo-keyword. In some cases it could be as useful as nil.
0 comments
Why does clicking the Forum link in the site ribbon always take me to the BBS > PICO-8 > Cartridges subforum?
I feel like it ought to be taking me to the BBS > PICO-8 root forum.
Even if your intent is to lead new users to the Cartridges subforum so they know it exists, it should really only do that from outside of the forum itself. Once I'm actually in the forum it feels very off to click Forum and end up with nothing but carts instead of general PICO-8 discussions. I keep doing this intuitively to return to the root forum, and then I remember I have to click the penultimate breadcrumb instead of the intuitive Forum link.
0 comments
I saw this mentioned on Discord, so I tested it, and found it to be true. I can't think of a reason for it to be this way, so I figured it should be written up as a bug.
This code:
local c=x+y |
is faster than this code:
local c=0 |
Here's a dead-simple test cart. Hold a button down to switch from running the first assignment per pixel to running the second. I get stat(1) = 0.7709 for c=x+y and 0.8296 for c=0, when at best they ought to be at least identical.

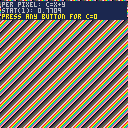
{kind=link} 5 comments
5 comments

Hey @zep,
I notice you can use the double-width katakana glyphs as identifiers, but I don't think you added the new printable single-width characters below chr(32) to the "legal chars" set for identifiers.
So I could use ta/た in a variable name, but because I need the single-width dakuten at chr(30) to make da/だ, I couldn't write a variable named, e.g., だくてん.
I figure if it's not a placeholder glyph (like the first 10 or so) and not reserved for Lua, it ought to be legal for identifiers, based on how every other glyph has been. Am I right?
I'm asking specifically because I'd like to use one particular character in place of 'self' in my code, to keep my code concise on the tiny PICO-8 screen, but I can't currently use it because it's not legal.
7 comments